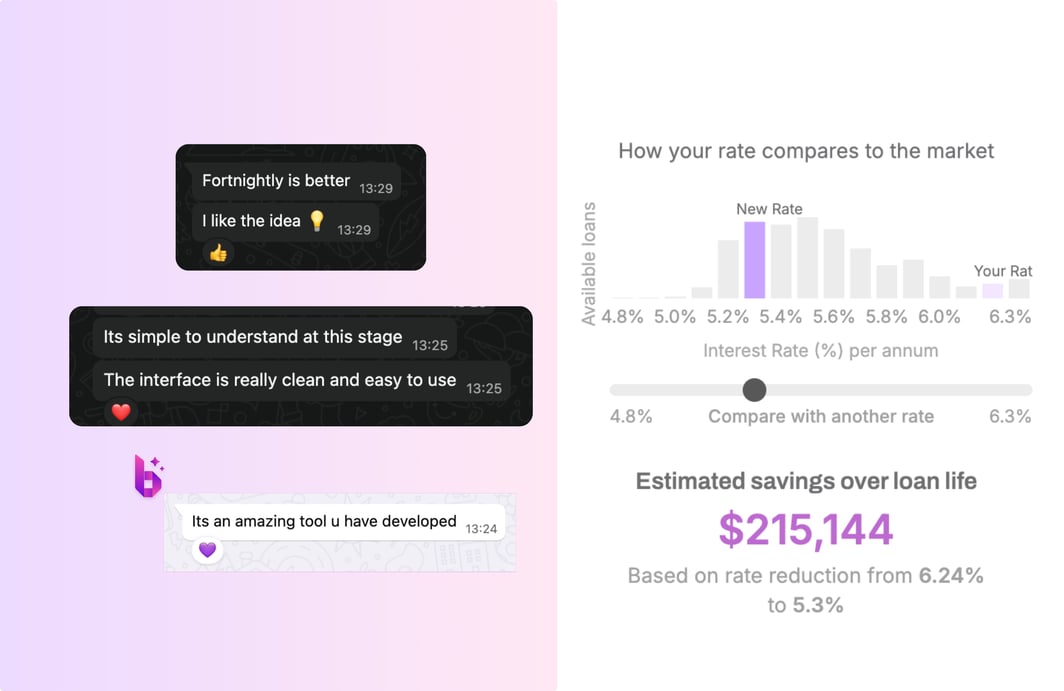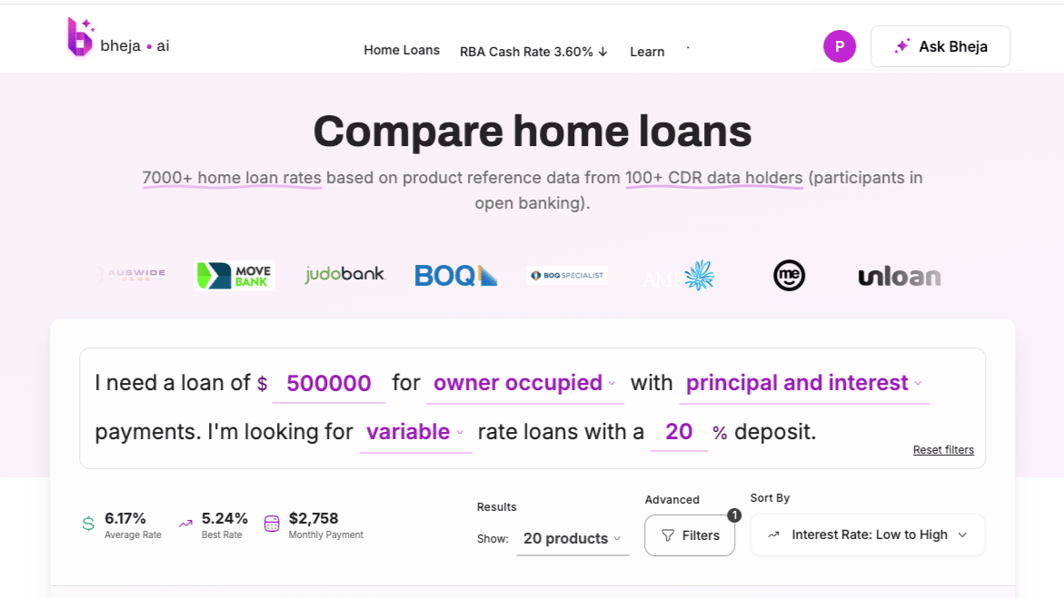
At Bheja.ai, we spent months trying to build a simple mortgage comparison tool using Australia's open banking data.
The data exists. It's technically available from 100+ bank endpoints.
But here's what surprise me: it's practically unusable.
Here's why—and how we fix it.
Australia's PRD is technically available but practically challenging. I've built tools to bridge the gap and want to collaborate with the ecosystem to make PRD truly ready for innovation.
The Promise vs. Reality
At the CDR Summit in Sydney last month, I found myself buzzing with optimism.
Everywhere I turned, during sessions, over coffee, in hallways conversation revolved not around whether we should share financial data, but how to do it in a way that genuinely supports innovation.
And yet, beneath the promise of open banking, there's a persistent friction:
Product Reference Data (PRD) is open in theory, but not yet ready for prime time.
PRD describes every loan, savings account, and digital product: everything from interest rates and fees to eligibility rules and service lifecycle details.
It's already published in machine-readable form by many Australian banks. But anyone who's tried to build comparison tools or automated quoting engines knows the frustration:
- Inconsistent formats
- Missing fields
- Subtle semantic differences
As someone who's built fintech tools, I've felt this pain firsthand. Integration costs that should be $10K become $100K because of data inconsistencies. The engineering cost can be crippling.
Why this matters more than just data
Picture this: You're building a fintech that recommends home loans.
You need to compare variable rates across multiple lenders, account for establishment fees, and factor in promotional periods. You don't want to maintain the data manually or warn users, "Rates may not be accurate."
Here's the kicker: PRD endpoints already exist for many banks, but a naive integration can mislead consumers.
The Data Standards Body (DSB) built the Product Comparator demo, which proves you can call unauthenticated PRD APIs and power a side-by-side comparison interface.
But the real lesson isn't that comparisons are possible.
It's that inconsistency across data formats stands in the way of reliability.
The ACCC's recent compliance review echoes this: missing fields, diverse fee structures, unclear lifecycle markers. Things that may sound minor but break fundamental trust.
The current landscape: available but not ready
The good news: wide availability
A broad swathe of Australian deposit-taking institutions already publish PRD endpoints.
Using the "Australian Open Banking Data Database" on GitHub, we have over 100 live endpoints, from major banks like: Commonwealth Bank, NAB, Westpac, ANZ, Macquarie, ING and to regional players like Bankwest and Bendigo.
The challenge: readiness gap
"Available" doesn't mean "ready."
The ACCC's review lays it out plainly: PRD is compromised by inconsistent semantics, missing attributes (like eligibility factors), and ambiguity in how fees, rate tiers, and product phases are represented.
Put simply: Your system might get some data, but getting accurate, comparable data? That's the hard part.
This isn't about criticism.
It's a disclosure layer that enables product owners to see what they're building with, reduces integration ambiguity, and supports faster, more confident development.
Critical Product Risks
1. Misleading Fee Comparisons
- Fees vary in naming (“Application Fee” vs “Establishment Fee”), structure (flat vs range), or are buried in text.
- Leads to apples-to-oranges comparisons that misinform customers.
2. Hidden Lifecycle Events
- Key details like promo expiries or revert rates are missing or deeply nested.
- Risk: customers select outdated products.
3. Eligibility Ambiguity
- Inconsistent or incomplete eligibility rules (LVR, income, occupation).
- Risk: showing loans customers aren’t actually eligible for.
4. Data Gaps & Standardisation
- 90% structured, but critical gaps in nested objects and missing fields.
- Risk: unreliable or incomplete product comparisons.
Our solution: Transparency through better tooling
AI-Powered Data Enrichment – LLM extracts missing details from unstructured text (e.g. hidden fees, eligibility conditions).
Intelligent Field Mapping – Flexible mapping handles inconsistent naming across lenders with graceful fallbacks.
Semantic Understanding – AI categorises products/features based on business logic, not just keyword matching.
Continuous Monitoring & Normalisation – Pipelines that restructure nested objects, fill gaps, and flag anomalies in lender feeds.
At Bheja, we’ve gone beyond raw PRD feeds. Instead of presenting complex, inconsistent lender data, we’ve built a blend of AI prompts and structured forms.
- This approach guides people to fill in the essentials (income, LVR, loan purpose, repayment type) in natural language or form fields.
- In the background, our AI normalises, enriches, and maps lender data into a clean, standardised structure.
- The result: a consumer-friendly home loan comparison experience where people don’t see raw tables
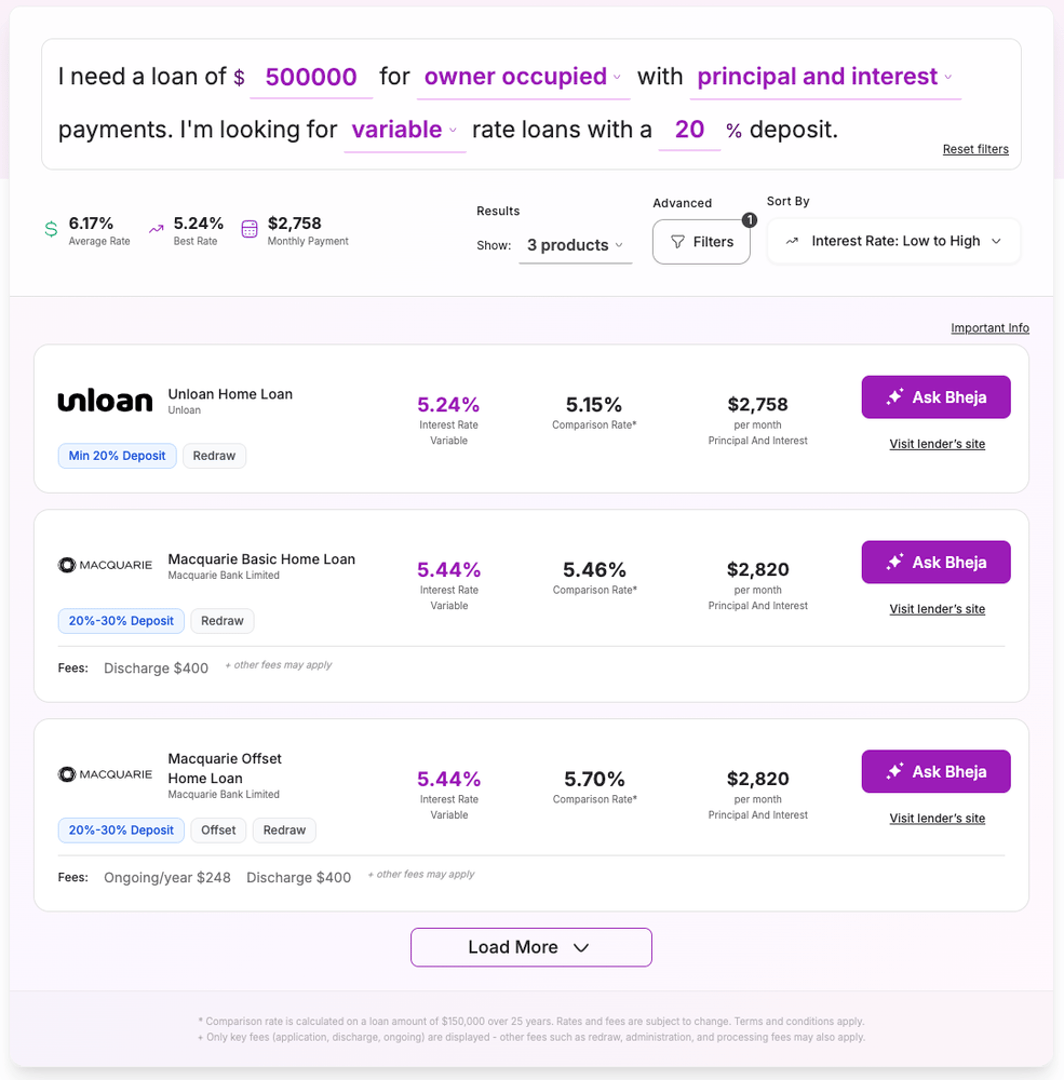
Simple easy to compare home loans based on the user needs.
Your invitation to build together
This article is a starting point, not an endpoint. We've already built comparison tables and normalisation tooling that we are ready to share for free. It not prefect yet and here we need you help.
Here's how you can get involved:
🏦 As data holders: Let's review your data together and identify improvement opportunities
🔬 As researchers: Reach out for data access and collaboration
🚀 As fintech builders: Let's explore partnership opportunities
🏠 As property owners: Tell me what features you need in comparison tools
🤝 As ecosystem supporters: Share this conversation and spread the word
The infrastructure is there. The regulatory framework is solid.
Now we need to bridge that final gap between "technically possible" and "practically powerful."
Working on PRD integration? Contact us.
#CDR #OpenBanking #Fintech #ProductReferenceData #Innovation #AustralianBanking #OpenData #API #DataStandards
Note : This article was originally published on LinkedIn.